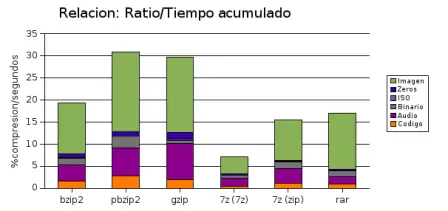
Los compresores de datos son todos distintos, aunque algunos utilizan algoritmos parecidos para realizar sus funciones y a ciencia cierta es difícil decir cuál es el mejor compresor, ya que depende del tipo de dato que necesitemos comprimir.
Los algoritmos de compresión más famosos son el algoritmo Huffman, el LZSS usado por WinRar y LZMA usado por el 7-Zip, aunque cabe aclarar que el 7-zip utiliza distintos módulos de compresión de datos.
Un algoritmo de compresión de datos básicamente puede funcionar eliminando espacios repetitivos o «redundantes» que se encuentren en series, es decir si se quiere comprimir un archivo que contiene la serie «AAAAAA» que sería el equivalente a 6 bytes se puede almacenar mejor «6A» que literalmente ocuparía 2 bytes.
Tipos de algoritmos de compresión
Básicamente se puede hablar de dos tipos de algoritmos de compresión, uno de compresión con perdida y otro de compresión sin perdida, sus conceptos son totalmente distintos aunque la finalidad sea la misma.
- Compresión sin pérdida: es el tipo de compresión que se usa principalmente cuando no se quiere perder ni un solo dato de una información determinada, pues lo que hace este tipo de algoritmos es reducir el tamaño sin eliminar nada.
- Compresión con pérdida: a diferencia del anterior este tipo de algoritmos elimina posibles espacios innecesarios para reducir el tamaño de la información.
Un ejemplo de compresión de datos con perdida son los compresores de imágenes, es decir, un caso puede ser un compresor de JPG que elimina espacios en las imágenes para reducir su tamaño, mientras que un ejemplo de compresión sin pérdida es el WinRar, para no perder la calidad de la información.
exelente 10